本文将从三个方面进行拓展:
什么是 A/B 测试?
A/B 测试(也称为拆分运行测试)是一种用户体验研究方法。它是一种随机实验,由具有 A 和 B 两个变体组成,同时运用了统计学上的假设检定。
A/B 测试是一种比较单个变量的两个版本的方法,通常是通过测试受试者对变体 A 和变体 B 的反应,来确定两个变体中哪个更有效。比如下图,通过为访问者随机提供网站的两个版本,这两个版本仅在单个按钮元素的设计上有所不同,因此可以测量这两种设计的相对功效。
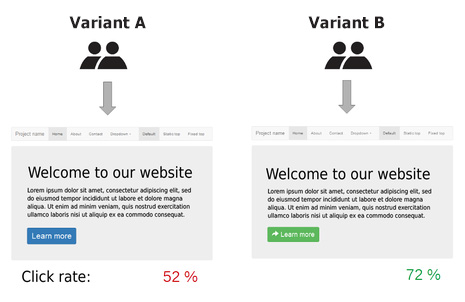
为什么要进行 A/B 测试?
1. 保持客观性
产品设计中,很容易犯的错误就是:将个人喜好投射到用户身上,“我觉得用户不喜欢,我觉得这个没用,我觉得这个功能对用户有用……”,每个人不同的知识背景、职业角色等都会影响他看问题的角度,从而影响客观性。
而当一个人决策的敏锐性以及经验缺乏的时候,更容易偏无事实或数据依据的主观性判断,也更易导致错误的决策发生。而 A/B 测试属于数据驱动,它可以帮助你使用数据化的设计方法,没有直觉、主观、猜测的余地,科学地优化你的用户体验。
虽然产品设计和改进看起来是基于主观的建立,但是通过 A/B 拆分测试,可以使你主观的想法变更为客观,因为收集的数据将支撑或反驳你的观点,帮助你做出正确的决策。
2. 从现有流量中获得更高的投资回报率
你的流量价值多少?你可以从现有流量中获得多大的投资回报?从数据跟踪我们可以直观看到,用户浏览都是呈漏斗型的,越往后,用户量越少。
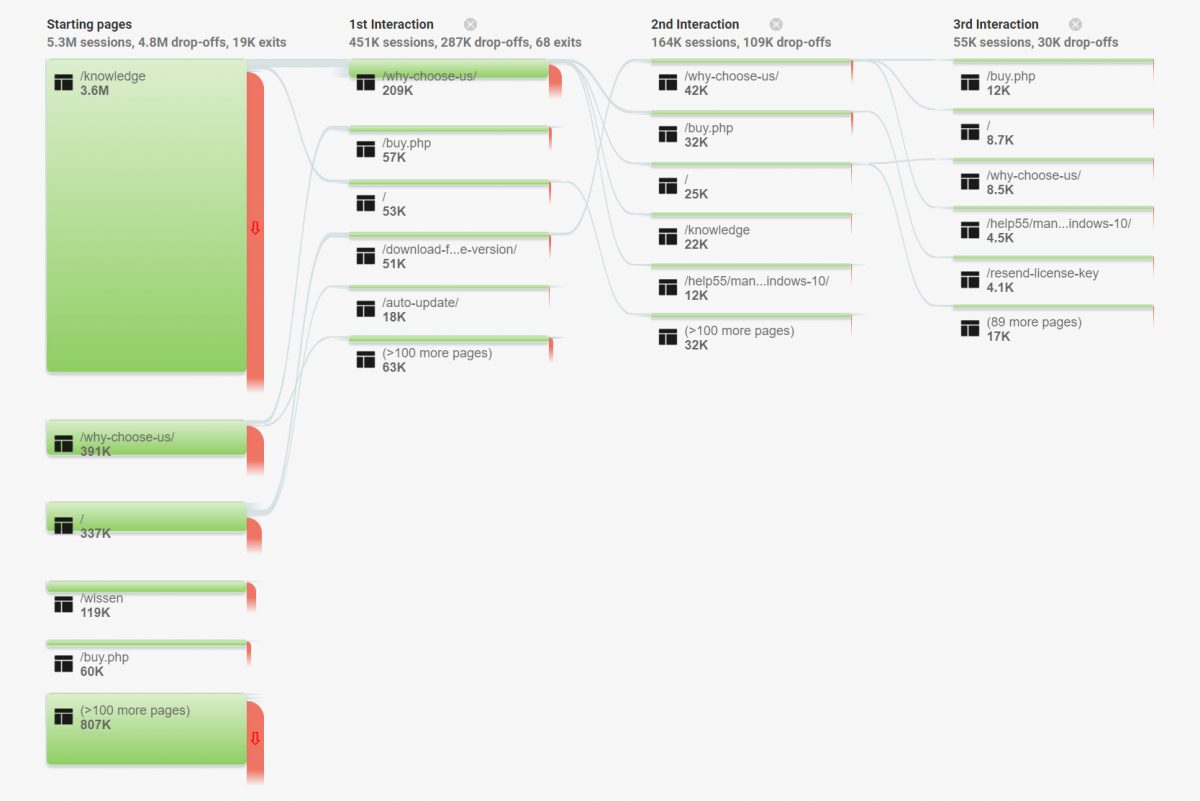
用户体验往往都是在研究用户的行为以及心理,它让我觉得有趣的是对人的洞察。令人困惑的设计,很难找到的下载/购买按钮……无论用户的目的是什么,每个阶段用户的想法、情绪、反应等,都会影响他下一步的行动。所以,任何一个环节的处理和设计不好,都可能会致使更多的优质用户(潜在客户)直接离开。
通过 A/B 测试,我们可以更合理并高效地进行多方面的尝试和探索,优化那些会影响转化率的因素,最大程度地利用现有流量,提高你的转化率,从而获得更高的投资回报。
3. 降低风险
当你想要进行重要或重大(涉及范围广、影响大)的修改,实现一个版本到另一个版本的过渡,也许你已经从方方面面尽可能地避免墨菲定律了,但是依然不能完全排除它会埋下一些未知隐患的可能性。
这时候通过 A/B 测试,它可以帮助你用最小的代价发现一些问题。因为测试是可控的,测试的变体有原始的参照物,这有助于你实时对比和观察数据的变化,发现异常可以及时停止,并进行数据对比分析,减少危害当前转化率的风险,让风险可控可预测。
4. 让修改具有意义
无论进行大小的增删改,可能是一段文字,可能是某个功能点,可能是重新设计整个页面,你不确定用户对这些修改会有何种行为和反应,你不确定你的修改带来的是正面还是负面的影响。
那么,进行 A/B 测试,对比同时期两个版本的表现,你可以清楚看到天枰会向哪一方倾斜,并根据统计上的显著性,轻松确定优胜者,这样会使结果具有确定性,以此为依据不断迭代并优化你的方案,并最终达到你的预期。
无论是原始的版本还是新的版本获胜(达到统计显著性),都可以算是一次成功的 A/B 实验,都具有一定的意义。它让你更了解你的目标群体,它让你明白什么样的修改会对你的用户产生影响等等。
在 A/B 测试中要避免的错误是什么?
关于这部分,我无法概括得比 VWO A/B Testing Guide 的更好更全面,所以,以下很多观点源自于 VWO,我将尝试用更通俗易懂的方式来让你理解它们。
错误 1. 未规划好你的优化方案
- 无效的假设:在进行 A/B 测试前,你需要针对你的目标制定优化计划。接下来所有的步骤都取决于此:应该更改什么,为什么要更改,预期结果是什么等等。如果你从错误的假设开始,则测试成功的可能性会降低,更难以达到你的预期。
- 用别人的话说:你从一些案例了解到,其他人改变了他们的购买页面,最后转化率增加了 30%,然后你进行同样的修改,并期望达到同样的效果,这种想法本身就存在一些误区,因为这是基于他们的流量、假设和目标得出的测试结果。没有两个网站是相同的,对他们有用的修改未必对你起作用,因为他们的流量会有所不同;他们的目标受众可能有所不同;他们的优化方法可能与你的不同,依此类推。它可以做为你最初建立假设的一个参考依据,但依然需要结合自身的目标规划你的优化方案。
- 一起测试太多元素:不要同时运行太多元素的测试。比如说,你想要进行购买页的优化测试,那么你需要计划好测试的优先级方案:你想要了解退款保证的效果;你想要了解价格的影响;你想要了解用户评论对转化率的影响等等。如果全部一起测试(太多元素),很难确定哪个元素对测试的成功或失败影响最大。
错误 2. 忽略统计显著性
A/B 测试是假设的检验方法。如果最初基于直觉或个人观点提出了假设,无论测试是成功还是失败,无论任何事情,都必须让它贯穿整个过程,以使其达到统计学上的显著性差异。因为即使是两个一模一样的版本进行 A/B 测试,转化率都会存在一个上下浮动过程,这种误差范围通常在 5% 以下,这是随机性导致的。达到统计学上的显著性差异,说明假设成立/发生的可能性在 95% 以上。
举个例子,我们用两个不同的购买页设计进行 A/B 测试,最后 A 版本的转化率比 B 版本的高,并且达到了统计显著性。那么这就意味着,A 的设计比 B 好的概率在 95% 以上,有 5% 以下的概率为两个版本的表现没有太大差别或者是 B 的表现更好,这 5% 的差异就是由随机误差造成的。如果测试的结果统计显著性未达到 95% 甚至 90%,那么,你需要考虑是否延长测试时间,或者中止测试(留意无效假设的问题)进行分析优化。
关于统计显著性的含义,统计学上的各种专业名词和计算能把你绕晕。通俗点理解其实就是用概率表示不可能发生和可能发生的临界点。你可以不了解如何计算出是否具有统计显著性这个过程,但是你需要了解它意味着什么。使用 VWO 的 Test Duration Calculator 或者下载使用它们提供的 Excel Spreadsheet,即可知道你的测试是否具有统计显著性结果。
无论好坏,测试结果都将为你提供宝贵的见解,并帮助你更好地计划即将进行的测试。
错误 3. 测试条件不理想
- 使用不均衡的流量:进行 A/B 测试的几个版本,应随机均衡分配流量。因为分配的流量具有随机性,会存在一定的误差,所以不会有数据完全相等的流量分配,流量的基数越大,将越趋于平均。均衡流量的随机性很重要,这是做 A/B 测试的前提,这意味着用户条件具有随机性,也就是说分配给 A 和 B 两组实验体的用户是相似的。同时,使用比测试所需的流量低或高的流量都会增加测试失败或产生不确定结果的可能性。
- 持续时间不正确的测试:根据你的流量和目标,对 A/B 测试运行一定时间,以达到统计上的显著性意义。运行测试时间过长或过短都会导致测试失败或产生不确定的结果。假如某个版本在开始测试的前几天就获胜,这并不意味着你可以立即停止测试并宣布获胜者,而应继续测试,观察结果是否稳定,但让测试运行太长时间也是企业犯下的普遍错误。
通过长期的 A/B 测试观察,如果没有太大的问题,我们通常选择 20-30 天的测试周期,这属于较为合理的范围,因为公司的站点流量足够大,充足的流量数据是保证测试的样本量足够多的前提,我们不需要通过较长的时间去累积足够的样本量。同时,经过长期的观察,10-20 天看到的结果基本是稳定的,但月初和月底有时会出现较大的一个波动,不排除会夸大甚至扭转测试结果差异的可能性。你实际需要运行测试的持续时间取决于测试期间的各种因素,例如现有流量,现有转化率,预期的改进等。 - 使用错误的工具:随着 A/B 测试的普及,多种低成本工具也应运而生。并非所有这些工具都一样好。一些工具极大地降低了你的站点速度,而另一些工具则未与必要的工具紧密集成(你利用来集成用户行为数据的工具,如 Google Analytics),从而导致数据的不准确性。使用此类错误工具进行的 A/B 测试,可能会从一开始就冒着测试结果错误的风险。
- 没有考虑外部因素:同一时间维度进行 A/B 测试是很重要的一点。因为这将使它们处于同一环境中,排除了很多外部因素的影响,这样进行的测试所产生的结果才更有意义。假如 A 和 B 没有处在同一时间,由于节假日、活动等一些外部因素导致 A 的流量/销量高于 B(比如双 11 购物节,销量明显高于日常),再将两者进行比较是错误的,因为无法排除这个结果受外部环境影响有多大。
错误 4. 无法遵循迭代过程
A/B 测试是一个迭代过程,每个测试都基于先前测试的结果。为了增加下一个测试成功的机会,你应该在计划和部署下一个测试时从上一个测试中汲取经验和见解。这样可以提高测试的优胜率,并获得统计上显着性差异的结果。此外,成功测试后也不要停止测试,不断迭代优化每个元素以产生最优的版本,即使它们原来是从上一次测试中获胜的一方。
错误 5. 坚持最简单形式的测试方法
A/B 测试被广泛认为是实验的最简单形式,从长远来看,坚持普通的、单一的 A/B 测试方法不会为你带来奇迹。通过添加多个变量或变体,将使测试变得更复杂,同时它也是有效的。比如,如果你打算完全改造网站的其中一个页面,则需使用多变量拆分测试,比较两个较大差别的版本。同时,如果你希望测试 CTA 按钮的一系列排列,比如它们的颜色、文本和图像,则需添加多个变体 (A & B & n) 进行测试。
扩展阅读哈佛商业评论关于建立实验文化的故事:


写下你的评论